Rebuilding Sequence Fulfillment


This a the story of optimizing an ancient, vital part of our service. Along the way we’ll highlight insights gained or proven in the fires of production deployment.
The problem
“Sequences” are our term for a pre-planned series of emails. Our customers decide what the emails should say and how long to wait between sending them. We make sure they go out at the right times to subscribers, relative to when they started the sequence.
We handle this by polling the database to see if it is time to send a subscriber the next email in their sequence. Since users can change their sequences and subscriber eligibility at will, polling is simpler than trying to predictively set up work.
This was one of the first features written for our service, and as we’ve grown it became slower and slower. We were able to temporarily address it by adding more database replicas to support polling. This was an expensive answer, especially as we started to outgrow our “temporary” extra replicas.
It was obviously not a sustainable solution.
Investigations
“Spending money” was not working. It was time to roll up our sleeves and do some engineering.
As with any performance problem, step one was figuring out what really was going on. We needed to dive into metrics, add some new ones, and get a solid answer for what was slowing things down. We already had records of how long each database query takes. We added to this with higher level instrumentation of the different phases of business logic, to get the whole picture.
Here we got lucky; the answer was obvious. As you might expect we have an “emails” table that contains a record of every email we’ve ever sent (well, had, but how we track that now is another story). Your second guess is also correct, we used this table to answer “what has a subscriber received and when”. The queries for this information stood out like a sore thumb in performance reports.
Planning
It was time to devise a plan. We came up with a short list of two core problems:
- The code involved was old, and a critical service, therefore by the laws of software maintenance it was crusty and hard to change without breaking
- Getting subscriber history from our emails table was expensive, since it predominantly holds non-sequence email records and is not well-indexed for the task
From this, we crafted our plan of action:
- Refactor the current code to be easier to change and allow sharing functionality. Along the way, fill out any missing tests
- Gather up low hanging performance fruit to buy time for harder changes
- Build out new tables and code for “position-and-history” records designed for this use case.
- Change the application to let us control which code is used
- Create those records without introducing downtime, impacting the service, or leaving room to doubt their accuracy
Testing and refactoring
The first step to optimizing an old hairy ball of code is never to fix performance. At best, performance optimizations make code very different. At worst, they make it more complicated. Neither are good for code that is already hard to understand.
So step one was to be sure our test suite was up to snuff and start pulling the old code apart. The goal was to change nothing about the behavior (including performance), just make it easier to reason about.
We performed a series of changes to extract pieces of functionality. This made it easier to think about that functionality, to review and test the change, and to later reuse pieces from our new implementation.
Easy performance wins
After that, we turned to finding optimizations in our existing (but now, easier to work with) code. Anything we could get out the door quickly would ease the burden for our infrastructure and support teams.
Right off we found a simple, valuable optimization. We allow “exclusion rules” for individual emails in a sequence. These define criteria for subscribers that should not receive that email. We were looking up all of these exclusions for each email every time we tried to send, and often not using them. We switched to only looking up exclusions the first time we checked an email. This relatively simple change bought us an average 5% speed improvement, with a 50% improvement in worst cases. More importantly, it significantly eased the strain on our replica databases.
We also tried a few iterations of looking up subscriber state in batches. Because of sequence-level exclusion rules, in almost all cases it was at best indistinguishable, if not slower. This is an unfortunate reality of optimizing large pieces of code dealing with large pieces of data. Chances are good that a promising lead in testing will not pan out in production.
The new system
While the above optimizations were happening, we simultaneously worked on the new system. The big win of this system was that it would be a separate set of database tables only for sequence fulfillment. These tables would be written to as part of recording email sends, so we could count on them to provide the same view of the position of a subscriber. Since they were dedicated to this task, we could set up ideal indices.
These tables had uniqueness constraints to speed up queries, and that we could lean on to insert data. The first was key to performance, the second shows up later in migrating the data.
With these tables, we could efficiently answer the key questions of “when was the last email sent” and “what emails have already been sent”. Because of our initial refactoring, it was easy to reuse pieces of functionality and run the same test suite over both the new and old solutions.
The big problem was getting the data into the new tables - without disrupting our service - in a way that let us be confident they were accurate.
Hustling data
The task of reproducing the position and history of 120 million subscriber/sequence pairs (the count at the time) is not hard, but it is time consuming. Since you cannot take the database down for several hours to shuffle data, you have to do it live while avoiding stale or inconsistent data. You also need to stay out of the way of normal production workloads.
To solve our consistency issue, we settled on the following key decisions:
- We would start filling the tables by processing all changes as they happened. This avoided concerns that backfilling could miss data
- Data inserts would use MySQL’s
ON DUPLICATE KEYclause, paired with unique indices, to guarantee that we either created new records or updated existing ones - Copying old data would also lean on indices, guaranteeing we did not have to worry about what had already been recorded through live updates
Our migration ran through a supervisor pushing tasks into a queue. Any time that queue backed up, or relevant key metrics started to lag, it stopped filling the queue. This allowed data copying to avoid disrupting already-struggling infrastructure. Because of our design constraints - and about a week of copying old data - we were fairly confident our new system would reproduce the results of the old one.
Unreasonable confidence
For this service, “fairly confident” wasn’t going to cut it. Errors could result in the wrong emails, or duplicate emails, being sent. We like that kind of stuff just as little as our customers do. We had tests telling us our results would be the same, now we had to prove it in the only other way possible: exhaustively running both systems and comparing results.
This started with random sampling. Production operations would flag a subscriber/sequence pair to check in both systems. This uncovered instances of bad data that we traced to interruptions in the original data copy. We addressed this by re-running the copy operation over the entire sequence where we saw evidence of a problem. When random sampling stopped finding issues, it was time to start exhaustive checks.
“Exhaustive checks” here meant loading up every single sequence and comparing results for every single subscriber. This comparison code had to be careful to not falsely flag cases where state changed in the middle of the test. Again, any time we saw a problem we would rebuild the new system’s data for the entire sequence. By this point we were about two weeks out from the original data copy, so we’d had plenty of time for issues with as-emails-are-sent updates to surface.
Our first run of those checks found a few subscribers random sampling had missed. The second time, we found no issues. Two more clean run-throughs left us with high confidence that the data was consistent.
Rollout
While those checks were happening we carefully reviewed the data for our marketing account, then turned on fulfillment for it through the new system. Since our new system and old system reported distinct metrics, it was easy to compare performance and identify errors. We built a dashboard to show every relevant metric for the migration and performance. Here’s what it looked like as we started switching over our production workload.
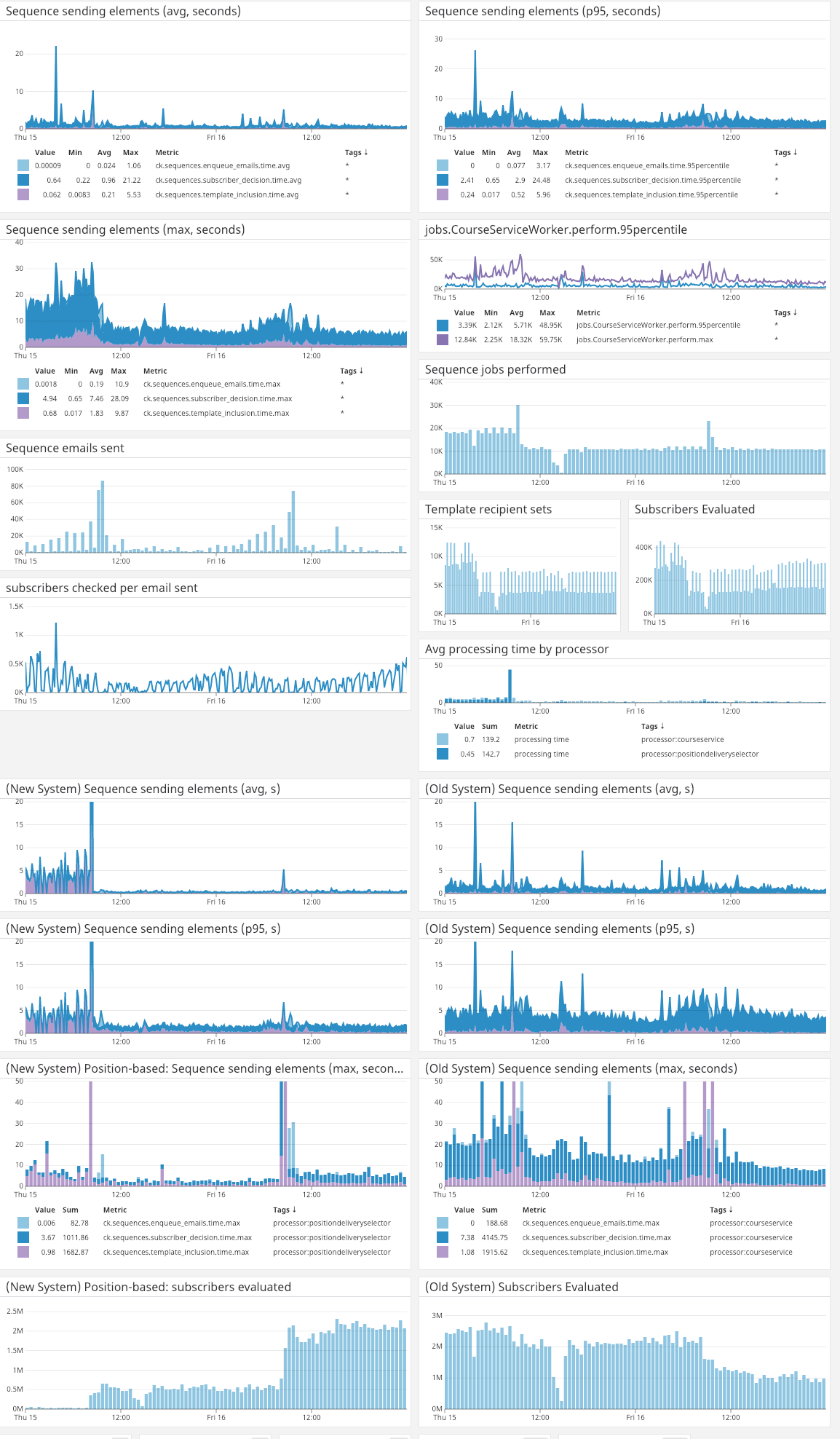
Note the “New System/Old System” side-by-side charts. These gave an at-a-glance performance comparison.
Once we were confident in our data and updates, we slowly cut over to the new system. We make extensive use of feature flippers, so it was easy to gradually move traffic to the new system (and quickly get it out if we identified a problem).
The rollout was the least incidental portion of the project. We took our time building out the feature and gaining confidence in it, then built a bunch of emergency failsafes anyway. All of that paid off in a smooth transition.
Results
No optimization story is complete without numbers. Here’s a comparison of three month periods before and after this optimization project:
Before:
- 95% of requests finished in 5 seconds or less
- Our highest runtime was around 25 seconds
- The average was about 2 seconds
After:
- 95% of requests finished in 2 seconds (a 60% decrease)
- Our highest runtime was around 12 seconds (a 50% decrease)
- The average was just under 1 second (another 50% decrease)
We also saw enormous benefits on the infrastructure side. Even with extra replicas, our infrastructure team would have to plan manual intervention to reduce server load around “rush hour” (every weekday from 10am to 12pm Eastern) when a large portion of our users have their emails scheduled.
This change significantly reduced the demand on our databases, allowing us to fully shut down one of the replicas and freeing time for our infrastructure engineers to focus on other tasks.
Wrapup
With hindsight, there’s a few things leading into this project we would have done differently. If we had responded to brittleness in this code earlier with refactoring, we could have saved significant time and stress. It’s scary to change important production systems. But, incremental attempts to minimize that fear lead to your most important code being an absolute mess. If we had followed incremental changes with well controlled refactoring, we wouldn’t have been trying to do that work while the application was struggling.
Likewise, we probably waited too long to make this change. We had a number of potential stressors on the database, and it took a while to isolate this one as significant. Relational databases typically drive multiple parts of your app. Any one part has potential to impact the others. It’s important to have deep insights to pick out which part is causing problems, and to be aggressive on deciding that slowdowns are a problem. This would have given us a longer runway to make the change, and fewer headaches trying to move mountains of data inside a struggling database.
It felt really good to watch a problem-free rollout that resulted in us shutting down an expensive database server. It took a lot of work and careful planning to make that happen, but the end results were worth it.