How to fix fragile rails tests — A process for fixing and maintaining your test suite


Have you ever written an awesome PR with solid passing tests and no bugs (obviously), merged it, only to see it fail in CI? Ugh. What happened? Did I miss something? Did I break something else? Can I safely deploy it?
Hoping it’s a “glitch” in your CI you re-run the build and… it passes. Wat?
If this sounds familiar you might have what we call “flappy” tests. Put another way, the tests are fragile. Fragile tests are frustrating, slow you down, and reduce confidence in your codebase.
We were in this situation and got out of it. You can too.
A process for repairing
1. Start tracking intermittent failures
Start by collecting failures in a single place so they are being tracked. We created one GitHub issue and whenever there was a failure a comment was added to the issue with the details of the failure. Include as much detail as possible and link to more if you have it. We included the randomization seed because some tests were failing due to the order in which they ran. We also linked to the results in CircleCI so it was easy to find the full stack trace.
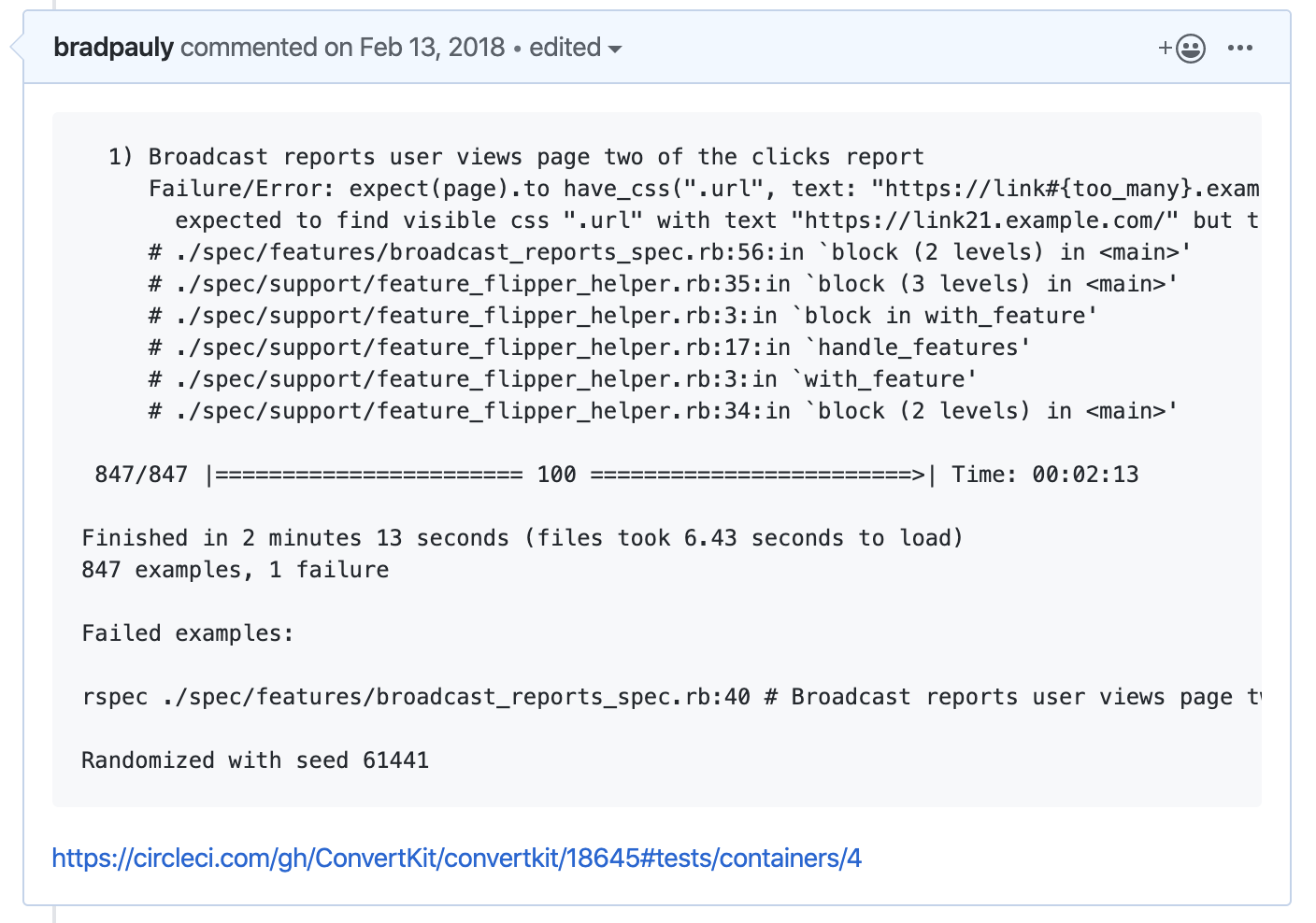
Encourage everyone to do this. It doesn’t matter why or how the test is failing, it’s important that the process is widely adopted. This raises awareness of the failure rate without the weight of feeling like you have to stop what you’re doing just because there was a failure. That will come later.
2. Start fixing the failures, one at a time
Now that the failures are tracked in one place, it’s easy to see what’s been failing and start fixing. Don’t try to fix them all at once. Start with a few a week. One or two is fine. Do this consistently and you’ll have them all done before you know it. Chances are good that one fix will repair more than one test. I can almost guarantee that you’ll start to see certain kinds of test failing. Once you tackle the first of its kind the rest will be much faster.
3. Set a goal and publish the success rate often
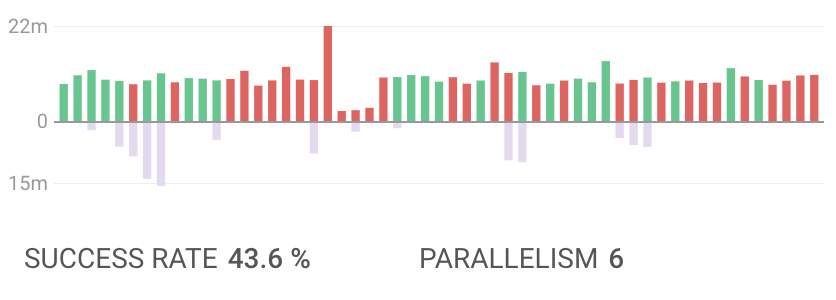
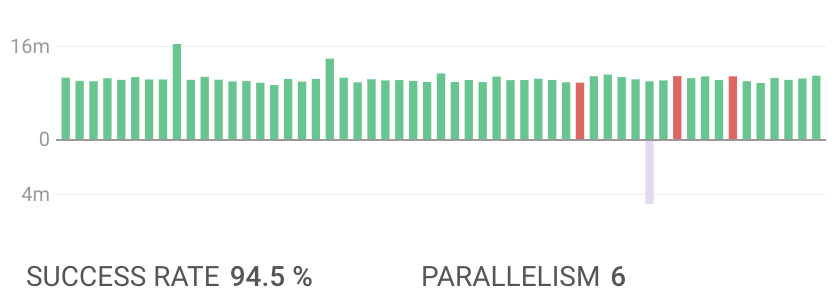
In May 2018 we were seeing success rates in the low 40%. We set a goal to get up to 80% and posted our success rate on a regular basis to share how things were going. At first it might feel like slow progress, but if you stick with some consistent fixing, you will see progress and it starts to feel really good.
This is a particularly bad week in May 2018.
And this is in December.
4. Share the common types of failures
If you identify any patterns in the types of failures you see as you fix them, share them with the rest of the team. We held a Lunch & Learn to review and discuss some of the common types of failures and how we could avoid them in the future. More on that below.
5. Keeping it resilient going forward
There will still be new “flappy” tests and that’s ok. However, now that your success rate is nice and high, try to fix any intermittent failures as soon as possible. We have a lightweight process for making sure we don’t ignore failures without slowing someone down when they are encountered. This is assuming that the failure is not related to the changes you are making.
- Skip the test so you aren’t blocked.
- Create an issue and assign it to the person that wrote the code that’s failing. It doesn’t matter if you assign it to the wrong person. It must be assigned to someone and can be reassigned if needed.
If your success rate is very high and stable, consider posting to a slack channel whenever master fails. This can be a distraction if it happens too often which risks losing its effectiveness. Bob (our ChatOps Slack bot) does this for us now and its great. A failure is rare so a colorful message in slack gets attention and the failure can be dealt with quickly.

Common failures
Time dependence
Tests that are dependent on comparing times can be tricky to reliably measure especially when the code uses Time.now. Tools like timecop can help, but its often better to inject a time so the code is not dependent on Time.now. Try moving the time out to where it makes a difference. For example, if you have a recurring job that checks for records updated in the last 5 minutes, when the job runs is a good place to inject the current time.
Record Not Unique
A hard coded id collides with a record created with factory bot. Do the extra work of creating a record and using its id to avoid duplicates.
Slow tests timing out
End-to-end integration tests are important and can be slow. If you find one that’s failing because it’s taking too long, make sure it’s still providing value. If you want to keep it, check your CI settings, you might be running into a limit there.
Row counts
If a test is expecting a row count to change and a parallel test inserts or deletes a row it will eventually fail. Counts are often a side effect of the process being tested. If the important part of the process is that a record is persisted, check it directly. If the count is important make sure the lookup is properly scoped so that parallel tests won’t affect it.
Conclusion
A robust test suite saves time and increases confidence. And a high level of confidence will increase your ability to ship quickly. If your tests start to become fragile, fix them as soon as possible. If it’s already fragile and seems like too much work to fix, take a step back, follow the steps above and you’ll be back at a high level soon.
Photo by Oli Woodman on Unsplash